Deploying machine learning models shouldn’t feel harder than building them—yet for many teams, it does. If you’re searching for clear guidance on MLflow model deployment, you likely want a practical, reliable explanation of how to move models from experimentation to production without unnecessary friction.
This article is designed to meet that need directly. We break down the core concepts behind MLflow’s deployment capabilities, explain how it fits into modern MLOps workflows, and highlight common pitfalls that slow teams down. Whether you’re working with local environments, cloud platforms, or containerized infrastructure, you’ll get a focused look at how to streamline deployment and maintain performance at scale.
Our insights are grounded in hands-on experience with machine learning frameworks, system optimization practices, and real-world production environments—so you’re not just getting theory, but actionable guidance you can apply immediately.
From Experiment to Production
You trained a stellar model—now what? Have you ever wondered why the hardest part isn’t accuracy, but reliability? Deployment is where many projects stall.
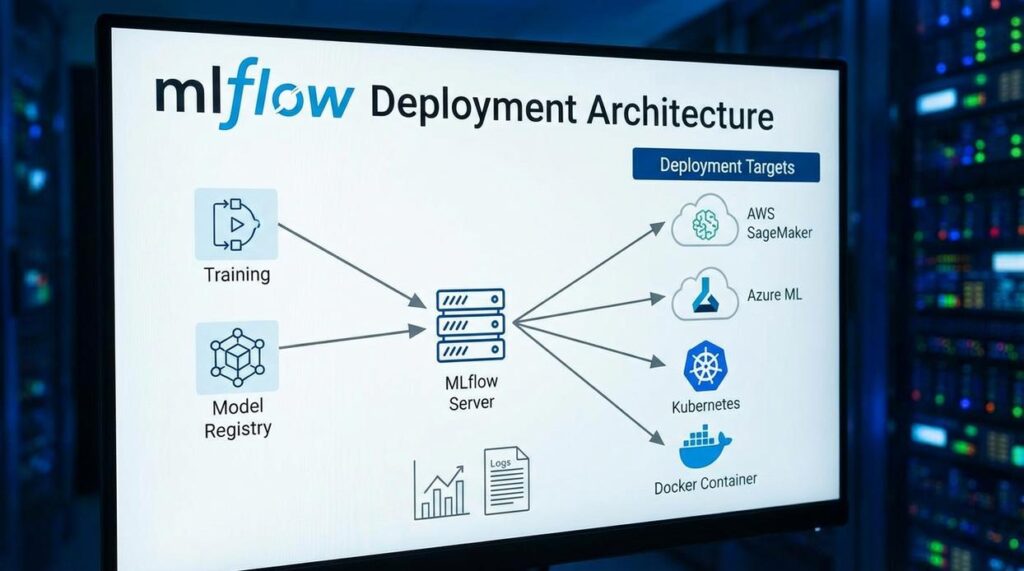
MLflow model deployment bridges that gap by packaging artifacts, dependencies, and environments into reproducible units. Instead of ad‑hoc scripts, you get versioned models, staged transitions, and controlled rollbacks (because surprises belong in movies, not production).
But which serving path fits you—local REST server, Docker container, or cloud endpoint?
Start with the Model Registry to promote models from Staging to Production safely.
Ask yourself: can your model survive traffic, scale, and monitoring demands?
Why MLflow Excels at Deployment: A Framework Overview
For those looking to streamline the deployment process, integrating insights from our article on ‘Python Llekomiss Code‘ can enhance your MLflow implementation and optimize your workflow.
MLflow is often praised for experiment tracking—but that’s just the opening act. Its real strength lies in the deployment ecosystem that turns promising prototypes into production-ready assets.
Beyond Tracking: The Real Advantage
MLflow Models introduce a standardized packaging format called “flavors.” A flavor defines how a model built in frameworks like scikit-learn, TensorFlow, or PyTorch can be loaded and served consistently. The benefit? You’re not locked into one ecosystem. That flexibility makes MLflow model deployment smoother across cloud platforms and local environments (yes, fewer late-night compatibility surprises).
MLflow Projects package code with its dependencies, ensuring reproducibility from training to deployment. If it worked once, it works again—same environment, same results.
The Model Registry acts as a lifecycle command center, enabling:
- Version control, stage transitions (Staging to Production), and team annotations
The result is faster releases, cleaner governance, and less operational friction—exactly what modern MLOps demands.
The Core Components: Understanding Flavors and the Model Registry
The Power of Flavors and Why They Matter
First, let’s define a model flavor. In MLflow, a flavor specifies how a model can be used. For example, sklearn, pytorch, and tensorflow flavors preserve framework-specific details. Meanwhile, the python_function flavor wraps any model behind a consistent prediction interface. In my opinion, this is the real superpower. It means your deployment code doesn’t care whether the model was built in PyTorch or scikit-learn (kind of like how every superhero still answers to “save the world”).
Because of this abstraction, MLflow model deployment becomes dramatically simpler. You standardize once, and everything downstream benefits.
Lifecycle Management with the Registry
Next, the Model Registry introduces structure. Models typically move through Staging (testing), Production (live traffic), and Archived (retired but stored). Some argue this is overkill for small teams. I disagree. Even lightweight projects deserve guardrails.
Versioning Is Key
Every registered model is automatically versioned. That means safe rollbacks and A/B testing—without changing application code.
Practical example:
import mlflow
import mlflow.sklearn
with mlflow.start_run():
mlflow.sklearn.log_model(model, "model", registered_model_name="SalesForecastModel")
Three Battle-Tested MLflow Deployment Patterns

When it comes to MLflow model deployment, I’ve found there are three patterns that consistently hold up in real-world environments. Some teams overcomplicate this step (as if shipping a model requires a moon landing checklist). It doesn’t have to.
Pattern 1: Local REST API Server
For quick testing, nothing beats spinning up a local server. The command is refreshingly simple:
mlflow models serve -m runs:/<RUN_ID>/model -p 5000
This launches a lightweight Flask-based REST API so you can send test requests immediately. It’s perfect for development, debugging, and stakeholder demos.
Some engineers argue this isn’t “production-grade.” They’re right. But that’s not the point. It’s a sandbox. You wouldn’t test-drive a race car in highway traffic, either.
Pro tip: Always validate input/output schemas locally before promoting a model. It saves painful rollbacks later.
Pattern 2: Docker Containerization for Portability
If you care about portability (and you should), containerization is the move. Use:
mlflow models build-docker -m runs:/<RUN_ID>/model -n my-mlflow-image
This creates a self-contained Docker image with dependencies baked in. In my opinion, this is the sweet spot between flexibility and reliability. It works seamlessly with Kubernetes and managed container services.
Some teams prefer manually writing Dockerfiles for control. Fair. But MLflow’s generator reduces human error and speeds up iteration. That trade-off is usually worth it.
And if you’re already thinking about performance at scale, understanding concepts like scaling neural networks with gpu and tpu acceleration becomes critical once traffic grows.
Pattern 3: Cloud-Native Deployment (SageMaker & Azure ML)
For fully managed endpoints, MLflow integrates directly with cloud platforms. For example:
mlflow sagemaker deploy -m runs:/<RUN_ID>/model -a my-endpoint
This abstracts infrastructure setup, autoscaling, and monitoring. You trade some low-level control for speed and reliability.
Personally, I think that’s a smart bargain. Unless infrastructure tinkering is your hobby, managed services let you focus on improving models—not babysitting servers.
Production-Ready: System Optimization and Best Practices
First, lock down dependency management. A precise conda.yaml or requirements.txt file ensures your production environment mirrors training—no surprise version conflicts, no “it worked on my machine” drama. Think of it as your model’s backstage rider: if one item’s missing, the show can fall apart.
Next, configure the serving environment thoughtfully. Pass environment variables for secrets like API keys rather than hardcoding them. This keeps credentials secure and portable across staging and production.
When it comes to monitoring and logging, build hooks directly into the prediction function. Track input data drift (when live data slowly stops resembling training data), prediction latency, and error rates. Over time, these signals reveal silent failures before they become headline outages.
Finally, allocate resources carefully. Define CPU and memory limits during MLflow model deployment to prevent bottlenecks and crashes. After all, even the Millennium Falcon needed the right upgrades to make the jump to hyperspace.
Streamlining Your End-to-End MLOps Workflow
At its core, MLflow removes the guesswork from taking a trained model to a live application. Instead of stitching together custom scripts, APIs, and deployment hacks (we’ve all been there), it standardizes the journey from artifact to endpoint. An artifact simply means the saved model file plus its dependencies.
The big win? You avoid building a new Flask app every time. MLflow model deployment packages models in a consistent format and handles the boilerplate.
- Register your next model in the Model Registry.
Then promote it from Staging to Production to see how structured lifecycle management simplifies everything.
Turn Your Machine Learning Models Into Real-World Impact
You came here to understand how modern machine learning frameworks and deployment strategies actually work in practice. Now you have a clearer view of the tools, concepts, and optimization tactics that turn raw models into production-ready systems.
But knowing the theory isn’t enough. The real pain point most teams face isn’t building models — it’s deploying, scaling, and maintaining them without breaking performance or reliability.
That’s where mastering MLflow model deployment and system optimization strategies changes everything. When you streamline experiments, track versions properly, and deploy with confidence, you eliminate guesswork and reduce costly downtime.
If you’re serious about building faster, scaling smarter, and avoiding deployment headaches, start implementing these best practices today. Explore the right tools, refine your workflow, and put structure behind your machine learning pipeline.
Stop letting deployment bottlenecks slow your innovation. Take control of your ML workflow now and build systems that are reliable, scalable, and ready for real-world demand.